noindexとは、特定のWebページや画像などのリソースをインデックスへ登録しないようにクローラーへ指示するために使われます。すでにインデックスに登録されていた場合はインデックスから削除され、検索結果からも完全に削除されます。
このように検索結果へのページの表示を制御できるのでSEOの一環としてnoindexはよく利用されます。この記事ではnoindexの使い方や使用する際の注意点などを詳しく解説していきます。
どんなときにnoindexを使うか?
どのようなときにnoindexを使えばよいのでしょうか?前述の通り、noindexは検索エンジンにページをインデックスしないように伝えます。これはつまり、検索結果にページが表示されなくなると言うことです。そのため、検索エンジンはこのようなページの内容を評価することはありません。
これを踏まえて、noindexは次のような場合に利用されます。
- 低品質なページが評価されることを回避する
- 不特定多数の人には必要のないページを検索結果に表示しない
低品質なページとは、内容が乏しく薄っぺらいページや他のサイトと内容が重複していてオリジナリティのないページなどです。サイトに低品質なページが多数存在すると、サイト自体の評価にマイナスの影響を与える可能性があります。
そのため、このようなページにnoindexを使いページを評価されないようにすることで、サイト全体の評価が下がることを防ぎます。
2つ目の「不特定多数の人には必要のないページ」とは、会員専用ページなどコミュニティの中だけで意味があるようなページです。このようなページは、検索エンジンからの流入は必要ないのでnoindexにするとよいでしょう。その他「404エラーページ」や「サンクスページ」など特定のユーザーへのメッセージなども同様です。
SEOの観点としては「すべてのユーザーに価値を提供できるページ」であるかどうか考えてみると良いでしょう。そのようなページでなければnoindexを使用する候補となります。
noindexの設定方法
noindexを設定するには次の2つの方法があります。
- HTMLのmeta要素に設定する
- HTTPレスポンスのヘッダー部に設定する
どちらを使っても効果は同じです。
HTMLのmeta要素に設定する
HTMLファイルであれば、meta要素でnoindexを設定することができます。meta要素での設定方法は以下に示す通り、name属性にはrobotsを指定し、content属性にnoindexを指定します。meta要素はhead要素の内側に配置します。
<head>
<meta name="robots" content="noindex">
...
</head>nofollowは、よくnoindexと共に使われます。記述方法は以下のよう、両者をカンマ(,)で区切って指定します。nofollowはリンクを辿らなくていいことをクローラーに指示します。head要素の内側のmeta要素に指定された場合は、ページ内のすべてのリンクを辿らなくていいことを意味します。
<head>
<meta name="robots" content="noindex, nofollow">
...
</head>反対に、followはリンクを辿るようにクローラーへ指示します。デフォルトでクローラーはすべてのリンクを辿るので、followを省略した最初の記述も、意味的には次のものと同じです。
<head>
<meta name="robots" content="noindex, follow">
...
</head>ただし、上記のようにnoindexと共にfollowを指定した場合、長期的には「noindex, nofollow」を指定した場合と同じになるとGoogleが表明しています。
これは簡単にいうと、検索エンジンはnoindexが指定されているページをインデックスしませんが、そのページのリンクを辿る必要があることはしばらくの間は認識しています。しかし、ページはインデックスされていないので、いずれそれも忘れ去られてしまいます。その結果、そのページのリンクは辿られなくなってしまうからです。
HTTPレスポンスに設定する
HTMLではない画像やPDFファイルなどでは、前述の方法は使えません。代わりにHTTPレスポンスのヘッダーでnoindexを伝えることができます。
HTTPレスポンスのヘッダーにnoindexを含めるには、Apacheの.htaccessファイルやコンフィグファイルで次のように設定します。
# .png、.jpeg、.jpg、.gifの拡張子の場合にHTTPヘッダーに「X-Robots-Tag: noindex」を含める
<Files ~ "\.(png|jpe?g|gif)$">
Header set X-Robots-Tag "noindex"
</Files>
# .pdfの拡張子の場合にHTTPヘッダーに「X-Robots-Tag: noindex」を含める
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex"
</Files>WordPressで設定する
WordPressであれば、プラグインや対応しているテーマを使って noindex を設定することができます。設定方法はプラグインやテーマのドキュメントを参照ください。
そのほか、function.phpなどを利用して設定することも可能ですが、コードを書く必要があるので少し難易度は高くなります。
noindex を使用する際の注意点
noindexを使用する際には、いくつの点に注意する必要があります。
- noindexを使用したページのクロールを禁止しない
- 検索結果からすぐには削除されない
検索エンジンはページをクロールするときにnoindexを認識しますので、noindexが有効に機能するためにはページをクロールできる必要があります。そのため、robots.txt でページへのクロールを禁止しているとnoindexは機能しませんので注意してください。
また、noindexを設定したからといって、検索結果からすぐに削除されると考えてはいけません。これは前述したとおり検索エンジンはクロールしたときにnoindexを認識するからです。したがってnoindexを設定した後、クロールされるまでページが検索結果から削除されることはありません。
ページが再びクロールされるまでの時間は長くなる場合があります。このような場合、Googleのクローラーにページの再クロールをリクエストしたり、Googleにインデックスの削除をリクエストして、ページ削除を促進することができます。
ページの再クロールをリクエストする
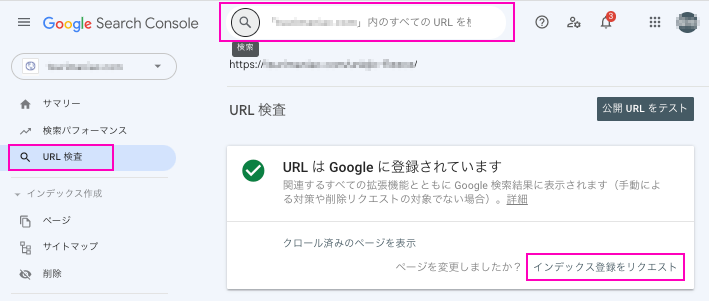
Google にページの再クロールをリクエストするには、Google Search Consoleの「URL検査」ツールを使います。リクエスをすれば速やかな再クロールが期待できます。
その方法は、Search Consoleにログインして、左メニューから「URL検査」をクリックし、再クロールをリクエストしたいURLを入力して検索します。それから「URL検査」ページの「インデックス登録をリクエスト」をクリックすれば完了です。
ページをインデックスから削除する
インデックスからページを削除することをリクエストすることもできます。
手順は次の通りです。
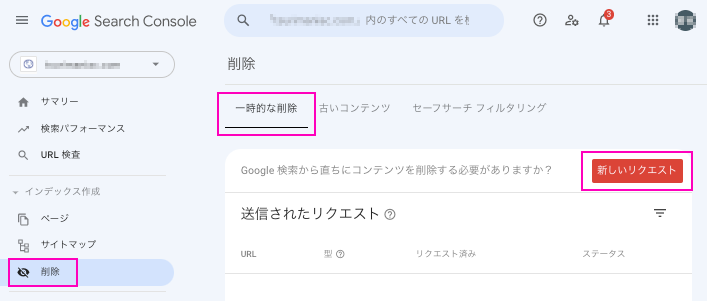
ブラウザでSearch Consoleにログインします。
左メニューから「削除」を選択し、「一時的な削除」タブの「新しいリクエスト」をクリックします。
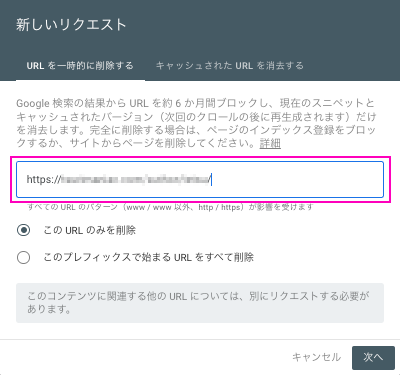
削除したいURLを入力し「次へ」ボタンをクリックします。
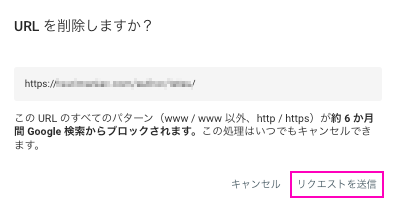
削除するURLを確認して「リクエストを送信」をクリックします。
「削除」ページにリクエストした内容が表示されます。
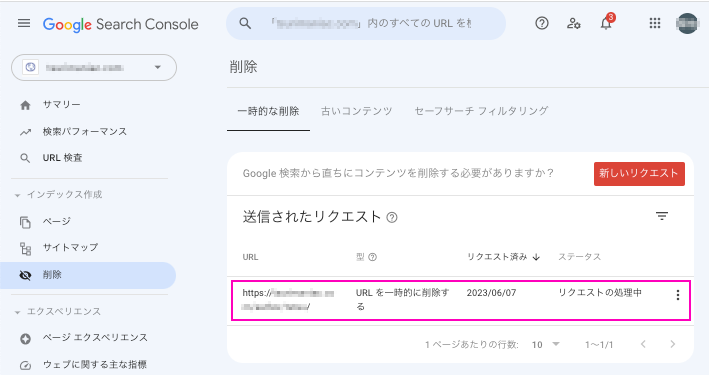
noindexが機能しているか確認する
noindexを設定したら、それが有効に機能しているか確認しましょう。それにはSearch Consoleを使います。
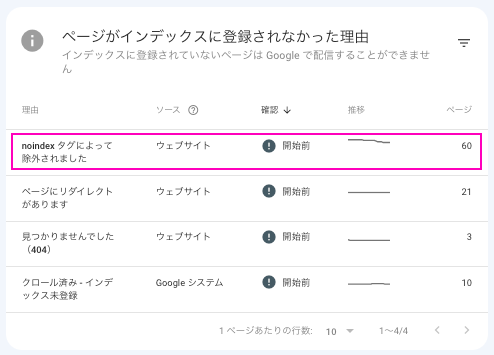
Search Consoleにログインして、左メニューの「ページ」をクリックすると、以下のような「ページがインデックスに登録されなかった理由」がページに表示されます。その中に「noindexタグによって除外されました」という項目で確認します。
「noindexタグによって除外されました」という項目をクリックすると、対象のURLがすべて確認できます。
おわりに
noindexを指定したときにGoogleの動作については「noindexを使用してコンテンツをインデックスから除外する」が参考になります。